ビンゴ5の第87回(2018年12月5日抽選)のAI(ディープラーニング)予測数字は、以下になります。
2つの予測値を提示します。ビンゴ5をご購入されている方は、ご参考までにご覧ください。
1,8,11,20,24,30,31,36 (セット球Aの場合)
5,9,15,16,21,26,33,36 (セット球Dの場合)
<変更点>
特徴量の次元を、2から3に変更。
これは、以前の当選数字の特徴をどこまでみるかという設定で、今回は前3回の当選数字の特徴をみて予測する設定にしました。
<テストデータの正解率>
43.6%
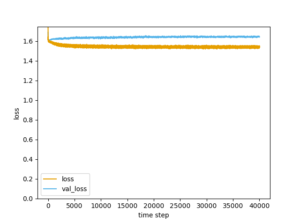
<損失関数>
テストデータの損失関数が発散してしまっているので、過学習になっていますね。
それで、正解率が43.6%と高くなっています。調整が必要ですが、今回は、これで様子をみましょう。
※
前回の予測情報の確認。セット球は、Hでしたので当たっています。的中した当選数字は、11の1個のみでした。
1個だと正解率は、12.5%です。2~3個当たるのが平均ですが、平均ですから、こういう場合もあるでしょう。
設定を変えます。
[↓前回の予測配信情報]
ビンゴ5の第86回(2018年11月28日抽選)のAI(ディープラーニング)予測数字は、以下になります。
2つの予測値を提示します。ビンゴ5をご購入されている方は、ご参考までにご覧ください。
4,6,15,20,22,29,35,40 (セット球Aの場合)
5,9,11,20,25,27,34,40 (セット球Hの場合)
※
AI予測方法としてディープラーニングを採用して実施しています。
ディープラーニングをご存知の方、ご興味のある方に参考まで情報を提示致します。
AI予測とひとくちに言っても、条件ややり方が違うと精度も異なります。
他の方が実施している予測結果とは必ず違うものとなります。
(同じ設定になることは、あり得ないとも言えます。)
特に当方の方法は、使用するデータを加工していますので条件が同じでも、
他の方が実施している結果と同じになることはありません。
BINGO5のセット球は8つあり、8つの予測結果がでる設定となっています。
当方の予測でセット球を2個に絞り、2個の予測値を出します。
いずれにしても、研究中であり不定期に設定変更を試行していく予定です。
(正解率50%を超えることができれば、販売データに移行したいと考えています。)
<ディープラーニングの実施条件>
プログラミング言語:Python
ライブラリ:keras
バックエンド:Theano
ニューロン数:[中間層1]100 [中間層2]64
Dropout:[中間層1]30% [中間層2]30%
エポック数: 40000
テストデータの割合: 10% (学習データ: 90%)
<使用データ>
特徴量の次元(入力の次元): 2 (当選数字の前の2回分の特徴を探す設定)
データ数: 664 (2018年11月22日時点までの全データを使用)
<テストデータの正解率>
正解率:30.2%
この数値は、単純には、テストで当選予測できた割合を示しています。
今後、過学習にならないように90%を目指したい。
言ってしまうと、現時点の予測では3割しか当たらないということで8個のうち3割ですから、2.4個なので
2~3個しかあたらない、と事前にわかるわけです
(平均でみるとですので、抽選会によってのばらつきがありますので、実際には1個だったり、4個だったりということですが)。
逆に見れば、正解率が低い数字を出して、消去法に使う方法もあるわけです。
そういったことも検討していきたいと考えています。
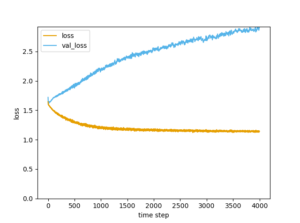
<損失関数>
損失関数は、過学習の有無を判定する指標です。発散する場合は、過学習がおきていることになります。
なんとか発散せず、過学習をまぬがれているが収束するには至っていない。
ゼロ付近に収束できるような方法を模索する必要がある。